中外搜索引擎研究的现状与发展
摘要:
以WWW网络搜索引擎的发展历程为基础,综述了WWW网络搜索引擎的定义、检索机制、检索规则、词表应用、分类研究、比较研究等方面取得的新进展,探讨搜索引擎发展走向与思路。同时就目前中外搜索引擎普遍存在的问题进行分析,希能对国内中文搜索引擎的开发和准确、快速、全面检索WWW网络乃至因特网信息资源有所启示。 关键词:搜索引擎 研究进展 综述 信息资源管理
由于因特网上信息资源内容广泛、时效性强、访问快速、网络交互搜寻、动态更新,而且还提供快速访问网上信息资源的各种搜索引擎(Search Engines),用于快速搜索WWW网络乃至因特上的有用信息,使得通过WWW网络获取网络信息资源成为国内外研究的一大热点。基于网络的搜索引擎的研制与开发应用成为当前网络信息资源开发应用研究领域的热点。英文搜索引擎“GOOGLE”和中文搜索引擎“百度搜索”的推出,拉开了搜索引擎核心技术争夺战的序幕。可以预言,在今后一段相当长的时间里,搜索引擎还将有长足的发展和进步,检索功能将更趋向于集成化和更具亲和力、更显人性化。 1 搜索引擎的定义、检索机制、检索规则和词表应用
1.1 定义
搜索引擎,Search engines,又称搜索机,Web搜索器,是伴随WWW网络出现的检索网上信息资源的新工具。实质上是一种网页网址检索系统,有的提供分类和关键词检索途径,有的仅提供关键词检索途径。它根据检索规则和从其他信息服务器上得到数据并对数据进行加工处理,自动建立索引,并通过检索接口为用户提供信息查询服务,能够自动对WWW资源建立索引或进行主题分类,并通过查询语法为用户返回匹配资源的系统。搜索引擎主要是由Crawler、Spider、Worm、Robot等计算机软件程序自动在因特网上漫游,不断搜集各类新网址及网页,形成数以千万甚至上亿条记录的数据库。它是通过采集标引众多网络站点来提供全局性网络资源控制与检索机制、将全球WWW网络中所有信息资源作一完整的集合、整理和分类、方便用户查找所需信息的网络检索软件。具有检索面广、信息量大、信息更新速度快,特定主题的检索专指性强等特点。 1.1.1 常规搜索引擎和元搜索引擎 自带索引数据库的搜索引擎通常被称为常规搜索引擎或独立搜索引擎,相应地,集多种常规搜索引擎于一体的搜索引擎则称为(多)元搜索引擎。元搜索引擎是国外搜索引擎开发者新设计的一种集成型搜索引擎,与独立搜索引擎的区别在于:它是通过一个统 一的用户界面帮助用户在多个独立搜索引擎中选择和利用合适的搜索引擎,甚至是同时利用多个搜索引擎来实现检索操作。元搜索引擎没有自己独立的数据库,却更多地提供统一界面,形成一个由多个搜索引擎构成的具有独立功能的虚拟逻辑体,通过元搜索引擎的功能实现对这个虚拟逻辑体中各搜索引擎数据库的查询等一切操作。由于元搜索引擎预先配置好多个搜索引擎,每条检索指令都自动通过预先配置 的搜索引擎执行,免去了用户逐一记忆和单独使用每个搜索引擎的麻烦。主要的元搜索引擎有ALL-IN-ONE、CUSI、Fun City Web Search、HyperNews、Linksearch、Savvysearch、Metacrawler、Best Search、W3Search Engines、WebSearch、Profusion、Mamma、Avenuesearch、Dogpile、Kwikseek、Findspot、Bytesearch、Webferret、Bluesquirrel Webseeker等。Metacrawler (http://www. metacrawler.com)能同时调用6个搜索引擎;Savvysearch (http://www. savvysearch.com)可有选择地调用21个独立的搜索引擎,检索Web、Usenet新闻组、软件、参考工具、技术报告等信息,每次最多并行检索5个搜索引擎的数据库。Profusion (http://www. profusion.com)最多同时调用9个独立的搜索引擎,调用方式有全部调用、系统自动选择最好的3个、系统自动选择最快的3个、用户从中选取任意个搜索引擎。最新出现的桌面型离线式搜索引擎如Webcompass、WebSeeker、WebFerret、Echosearch、Copernic98等也是元搜索引擎。 1.1.2 集中式搜索引擎和分布式搜索引擎 基于搜索机器人的搜索引擎如AltaVista和目录式搜索引擎Yahoo从体系结构上看都是集中式的,从因特网上取回Web页,经过处理后将所有这些信息集中存到某个站点,用户通过访问该站点实现查询,通常它们之间没有协作,各自独立地搜集和处理信息,造成了大量重复工作,也浪费了网络带宽和CPU资源,给各Web站点带来了严重的负担,这种集中式的体系结构难以适应网络规模的日益扩大。分布式搜索引擎则可弥补这方面的不足。其基本思想是根据地域、主题、IP地址或其它的划分标准将全网划分成若干自治域,在每个自治域内分设检索服务器(Index server),每个检索服务器由信息搜集软件(Gather)、索引数据库(Index database)和代理(Broker)三部分组成,信息搜索软件负责本自治域信息的搜集,并建立索引信息存入索引数据库,代理则负责向用户提供查询接口,并与其它代理进行交互,实现检索服务器之间的中间信息交换。关于分布式搜索引擎,目前主要以理论研究为主,还没有出现实际营运的研究成果。国内有文献提出建立分布协作式搜索引擎的设想,其主要思想是以CERNET为依托,在其不同域内分别建立搜索引擎,并通过引擎注册机制和引擎间数据交换机制相结合的方法实现网络搜索引擎之间的协作,达到降低资源消耗,提高搜索引擎效率的目的。 1.2 搜索引擎的检索机制 搜索引擎定期自动搜寻有关Web站点、采集关于这些站点上的各类信息,自动对这些资源进行标引、编制目录和文摘,自动将这些数据整合到数据库,并能提供以Web为基础的包括布尔检索、短语或词组检索、自然语言检索和各种限制检索在内的数据检索,按相关度输出检索结果 。搜索引擎的主体部分包括了数据采集模块、数据组织模块和数据检索模块。对应地,其资源组织和检索机制包括了数据采集标引机制、数据组织机制和用户检索机制,见图一。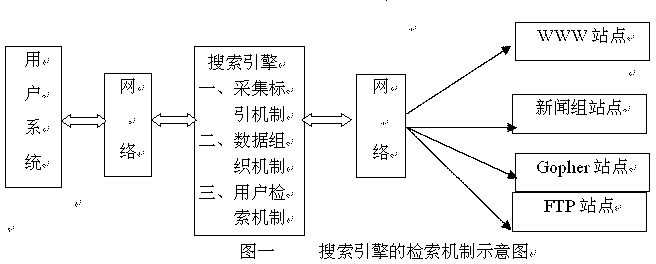 1.3 检索规则研究
由于Web资源的特殊性,搜索引擎的检索语法和检索规则与传统的光盘检索和联机检索等有所不同。Medscape、Oncolink等医学搜索引擎通过AltaVista完成搜索任务。AltaVista的检索语法规则较为复杂,基本上囊括了医学搜索引擎的检索规则。Medscape和Oncolink为代表的搜索引擎检索规则主要包括:
布尔逻辑操作符。包括:AND(;、&)、OR(,、|)、NOT(—、!),此外逗号“,”类似于OR,空格和分号(;)类似于AND。
短语检索使用双引号,如“radiation enteritis”。如要查找数字信息,如“1 800 555 1212”,可用破折号“—”连接“1—800—555—1212”作为短语进行检索。
大小写有别(case-sensitivity),如输入brca1,可查找brca1,Brca1和BRCA1,如输入Brca1,则只能查找“Brca1”的网页,不能查找brca1、BRCA1的网页。
+/-号,如要查找乳腺癌治疗但非放射疗法的信息,输入breast+treatment-radiation进行精细检索。同样,如要查找异基因骨髓移植而非自体骨髓移植的信息,输入“bone marrow+allogeneic-autologous”即可。
截词检索,使用通配符“*”,也有使用“$”或“?”;英文句点“.”的作用正好与通配符相反,用于禁止单词扩展,如gene.不能检索genetics、genetic、general等词;
,
1.3 检索规则研究
由于Web资源的特殊性,搜索引擎的检索语法和检索规则与传统的光盘检索和联机检索等有所不同。Medscape、Oncolink等医学搜索引擎通过AltaVista完成搜索任务。AltaVista的检索语法规则较为复杂,基本上囊括了医学搜索引擎的检索规则。Medscape和Oncolink为代表的搜索引擎检索规则主要包括:
布尔逻辑操作符。包括:AND(;、&)、OR(,、|)、NOT(—、!),此外逗号“,”类似于OR,空格和分号(;)类似于AND。
短语检索使用双引号,如“radiation enteritis”。如要查找数字信息,如“1 800 555 1212”,可用破折号“—”连接“1—800—555—1212”作为短语进行检索。
大小写有别(case-sensitivity),如输入brca1,可查找brca1,Brca1和BRCA1,如输入Brca1,则只能查找“Brca1”的网页,不能查找brca1、BRCA1的网页。
+/-号,如要查找乳腺癌治疗但非放射疗法的信息,输入breast+treatment-radiation进行精细检索。同样,如要查找异基因骨髓移植而非自体骨髓移植的信息,输入“bone marrow+allogeneic-autologous”即可。
截词检索,使用通配符“*”,也有使用“$”或“?”;英文句点“.”的作用正好与通配符相反,用于禁止单词扩展,如gene.不能检索genetics、genetic、general等词;
,,限定范围,如新闻title;/n,如digital/100 television二者的间隔不超过100个单词的网页。
t、u的使用,t(TITLE)加关键词前,搜索引擎只检索网站名称,u(URL)加于关键词前面,仅查网址。
精细检索:在特定主机或特定域名中查找网页、查找包含指向自己Web链接的全部网页,如查找包含一类特定Java语言的全部网页。超链和锚关键词在查找有关“jump”信息方面的作用相似。Link关键词查找URL带有跳跃性的网页如:http://www.abc.org/help.html,而anchor关键词查找用户能在页面中看见的超链文本,如click here,文本和标题标记用于查找网页内容。Text关键词查找网页内任何可见的文本词(非标记、链接、URLs),而标题关键词仅限于作者编码为title标记的文本,题目出现在Web浏览器的旗标窗口中。
禁用词的使用。在MedHunt等搜索引擎中,检索时规定了一些禁用词,如冠词、代词、介词和连词,此外还有一些其它禁用词:如back、top、up、down、net。医学术词中带有禁用词的术语MedHunt可识别,如“Vitamin A”,不视其为禁用词(http://www.hon.ch/MedHunt)。
此外,还可将检索词的间隔范围限定在句子或段落中(如、)、限定检索信息范围(每页显示信息条数,显示的语种、显示模式、匹配模式)等。
相关性排序。Oncolink主要依据下列规则进行结果排序:检索词或短语是否在网页的前几行(如Web页的标题);在一个三个词的检索提问中,包含三个检索词的网页将比只包含一个词或两个词的网页远远排在前面;不常出现在索引中的检索词较普通词的权重更大,每个网页的权重值是出现在网页中所有检索词的权重和,权重值最高的网页在结果表中排在最前面;一个词在网页中出现次数的多少不影响排序,检索词只出现一次的网页与检索词在其中出现50次的网页权重相等。WWW网络搜索引擎试图以检索词的词频、在文中的位置、以及检索词的相邻程度等依据判断检索结果的相关性,Magellan使用的“personal library software”除依据这三条标准判断检索结果的相关性外,还考虑检索词在数据库中的独特性及每个检索提问包含独特检索词的数量。
1.4 词表应用
据《叙词表指南》的统计,叙词表有500多种。由于目前标识HTML文件题目的词一般都是使用自由词,随意性大又不受控制,所以搜索引擎无法定位和鉴别,造成网络信息查全率、查准率低。随着信息资源的迅速增加,信息资源的组织控制发生了一些新的变化,Dublin Core和 URC等一系列元数据格式在Web资源组织和控制上得到了应用。词表在搜索引擎的应用,提高了检索针对性、准确性,且使搜索引擎趋向智能化。搜索引擎是WWW网络信息资源组织和检索的最主要方式,其理想的知识组织模式应当是建立一个结构简明的知识分类体系和智能化控制词表,实现对作者语言和用户语言的控制转换,实现自然语言检索和控制性语言检索一体化。美国著名情报学家兰开斯特(Lancaster)提出,采用一个较粗泛的控制词表,也许只包含几百个词,提供系统的全部上层结构,文献标引在一个或几个这种粗泛的叙词之下。自然语言可以使检索有一定的专指度,而粗泛控制词表可提供族性检索,并可给出自然语言的上下文。因此,最好是把控制词汇同自然语言结合起来。
美国国立医学图书馆(NLM)研制的一体化医学语言系统UMLS在IGM中的应用使得IGM对MEDLINE数据库的检索趋向智能化。UMLS由超级叙词表、语义网络、情报源图谱和专家词典组成,是NLM主持研究开发的生物医学检索语言集成系统,它不仅可以克服不同系统检索语言的差异,而且实现了跨数据库检索的词汇转换,帮助用户对计算机化的病案系统、书目数据库、事实数据库、图像数据库和专家系统等各种联机情报源中的生物医学信息作一体化检索。目前UMLS已在Medical World Search和CliniWeb International两个医学专业搜索引擎中得到应用。
2 搜索引擎的分类研究 WWW网络搜索引擎不仅数量增长快,而且种类也比较多。但目前尚无统一的分类标准。以下是一些主要的分类方法: 2.1 按索及资源内容的详略划分,有目录型、全文索引型、文摘型。 2.2 按索及资源的来源划分,有万维网和非万维网检索工具。 2.3 按覆盖范围划分,有通用查询引擎和专业查询引擎。 2.4 按检索方式划分,主要有关键词索引、主题指南和元搜索引擎 ,或按范畴层次查询的搜索引擎和词语查询引擎。有的将医学搜索引擎划分为目录型、检索型、评价型和汇集型,此外,还有作者将搜索引擎划分为分类主题目录、搜索引擎、主题索引、多种合一的集成检索工具。也有文献将其划分为检索型、目录型和混合型检索工具;或浏览式、按主题指南分类目录查询方式、利用检索软件进行关键词或自然语言的查询方式、集成式和多线索的查询。 2.5 按检索机制划分,有常规搜索引擎和元搜索引擎,或单独型和集合型检索工具;或人工分类式、自动搜寻式和混合式搜索引擎;或基于目录的搜索引擎、基于机器人的搜索引擎、基于客户的搜索引擎、元搜索引擎、分布式搜索引擎。离线式搜索软件需下载后安装运行方可进行检索,这类离线式搜索引擎多为元搜索引擎,主要有TURBOSTAT、WEBSEEKER,飓风搜索通、小猎狗、SEARCHX等中外离线式元搜索引擎。以上各类型搜索引擎,除分布式搜索引擎尚无实际营运的研究成果外,其他类型的搜索引擎均已有较多的实际应用。
3 搜索引擎的比较研究 搜索引擎的功能在于将分散的网址集中起来,分类提供给用户,以便快速查找到所需的信息。常规搜索引擎一般都带有数据库资源,因此对搜索引擎的比较主要集中在数据库资源和搜索引擎的性能两个方面。数据库资源方面的比较研究主要包括:数据库规模、索引方式、以及资源内容(如声音、图像、Usenet、FTP、Newsgroup、Gopher、Email等其它资源)。检索性能的比较,主要有布尔检索、复杂布尔检索、相邻和相邻and/or检索(NEAR、ADJ、FAR、BEFORE、FOLLOWED BY、、)、截词检索、检索范围限定、出版日期限定、多语种检索、多种版本选择、大小写有别、概念检索、词语加权、词语限定、自然语言检索、特定字段检索、缺省值、检索结果显示方式、显示数量选择、相关排序、站点评价、相似性检索、结果过滤、用户界面、查准率、响应时间等方面的比较研究。
3.1 国外的比较研究
国外学者对Alta Vista、Excite、Lycos从检索方式、响应时间、准确性等方面进行比较与评价,Alta Vista检索功能较强,Lycos的覆盖范围较广,Alta Vista真正地支持词语检索。不同搜索引擎的检索结果有很大差别,由于医学搜索引擎的检索功能不够强大,在解决临床提问时所获得的相关文献不多,平均仅解决了1个提问,医学搜索引擎出现了相关检索结果为0的现象,检索的相关网页数明显少于通用搜索引擎,医学搜索引擎提供信息的质量有待提高。有研究认为,权威医学医学数据库(Medline、EM)仍然是卫生专业人员和其他人员的第一选择。此外,即使功能最完善的搜索引擎也只能找到Web上大约1/3的网页,1998年6种主要搜索引擎的Web网页搜索覆盖率:HotBot 34%;AltaVista 28%;Northen Light 20%;Excite 14%;Infoseek 10%;Lycos 3%。1999年被测试的11种搜索引擎中查询到网页最多的前三名是NorthernLight、Snap、AltaVista,没有任何一种搜索引擎可以包罗超过16%的网上信息资源,搜索引擎的覆盖能力与一年前相比明显萎缩。 近些年来陆续出现了许多比较网络检索工具的研究和报道,绝大多数研究是就一些检索提问,比较和评价多个检索工具,采用的比较和评价标准不统一。随后,又出现了专门汇集此类研究和报道的联网书目,http://www.ub2.lu.se/desire /radar/lit-about-search-services和http://state.Wi.us/ agencies/dpi/www/srch_bib.html,它们为用户比较和评价国际互联网检索工具提供了方便。
3.2 国内的比较研究
国内对于搜索引擎的比较研究主要在两个方面:一是对搜索引擎的基本检索性能和数据库内容进行比较;二是通过一定的检索提问进行上网测试。已有作者从数据库的内容和结构、检索方式及特点、检索结果的显示、数据库的更新及有无扩展功能等方面四个方面加以比较,发现目录型检索工具Yahoo、Librarians'的检索功能相对较弱,检索型检索工具的检索功能则相对较强。在布尔逻辑检索方面,仅仅少数搜索引擎做得比较好。Infoseek和Open Text为检索结果提供了很好的描述,Open Text是唯一支持全文检索的引擎,Lycos、Excite、Open Text是覆盖面较广的数据库,Yahoo是较完整的目录。国内作者对多种搜索引擎的比较测试表明,对同一检索式,不同检索引擎的检索结果相互交叉的现象不多,各搜索引擎检索出的条数有较大差别,元搜索引擎检索出的结果不一定比单一搜索引擎多。有作者发现,Alta Vista、Excite、HotBot、Infoseek、Lycos、Open Text、Webcrawler、Yahoo以及中文搜索引擎Goyoyo在索引资源、用户界面、功能设置、检索速度、检索数量以及准确率等方面各有所长。也有人对中文搜索引擎进行了网络测试。与传统的光盘数据库检索相比,因特网信息缺乏深度、质量和可靠性不稳定,搜索引擎查询和光盘检索在用户服务方面均有优势和不足。国外知名通用搜索引擎Yahoo、AltaVisat、医学搜索引擎HealthAtoZ、Medical Matrix、Biomednet、MedWeb、 Cliniweb和MedWebplus等都有其各自的特色与优点,但都是互相补充,而不能彼此替代。
表一 国内外常用WWW网络搜索引擎一览表
4 存在的问题 WWW搜索引擎的分类方法不统一,缺乏权威的分类标准,国内有关WWW搜索引擎的分类研究更显薄弱。 无论从评价标准、评价方法和评价范围来看,目前的研究还不够深入,尽管有大量的搜索引擎比较研究论文,由于缺乏统一的标准和权威的评价指标体系,还要从理论上进行深入探讨,并开展更具规模和系统性的分析和评价工作,形成权威的评价站点和搜索引擎性能评价指标体系。目前国内还没有出现WWW网上的权威评价站点,国内的搜索引擎评价标准多是综合或借鉴了国外的研究成果,有所创新的评价研究和评价指标并不多见,网络中文信息资源和搜索引擎性能评价也还刚刚起步。当然,网上中文信息匮乏也是带普遍性的问题。在国际数据库市场中,数据库产品的地区分布为北美占64%、西欧占28%、亚洲占4%、澳洲占2%、非洲和南美洲1%;发展中国家对数据库的占有量不到5%,在亚洲只有日本、韩国有100种以上的数据库产品进入国际数据库市场,各为143、132种,中国只有4种。在国际各类数据库中,11.26%的数据库在100万条记录以上,其中超过1亿条记录的占0.36%,2.78%的数据库在1000万-1亿条之间,8.03%的数据在100万-1000万条间。除了大型数据库外,其余数据库平均记录在11.3万条左右;国内29家单位142个数据库的调查表明,10万条以下的数据库占72.32%,大型数据库仅占5.6%,尚无超过1000万条记录的数据库。中文信息不全,质量不高,也是制约中文搜索引擎进一步发展并推向国际市场的重大障碍。 WWW搜索引擎的选择也是仁者见仁,智者见智,多是根据经验的初步选择,还没有形成一套固定的选择原则和方法。WWW信息查询还不可能取代技术成熟的联机检索和光盘检索。据估计,因特网上目前有3000万URL和35亿页文件,而且文件数量每年增加一倍,迄今搜索引擎尚存在以下主要的问题:即使最强有力的搜索引擎也只能覆盖其中的1/3;查准率不高,检索精度不如传统检索系统;更新速度慢而且无法控制网络信息的动态变化;此外对信息内容的表达和格式的多样化难于控制和管理。 WWW中文搜索引擎带有的数据库容量小,尚未形成大型的检索系统,大型、综合、集成的元搜索引擎还没有开发出来,专业性和专题性中文搜索引擎亟需研究开发。基于WWW的因特网检索越来越普遍,信息过载成为日益紧迫的研究问题;电子期刊全文数据库提供的信息时滞参差不齐、蕴含的信息量少于印刷本期刊。 信息组织的局部有序性与整体无序性。各搜索引擎和站点目录都收集大量的站点,并按专业和文献信息类型分类,实现了信息组织的局部有序化,但仍有大量信息被湮灭在信息的海洋里,这种无序性导致了网络信息检索的系统性和完整性不如商用联机检索系统,此外,有害信息(黄色、吸毒、暴力宣扬)多,不安全因素有增无减,缺少一个统一的监督机构,信息泛滥造成了信息污染和资源、时间的浪费。多媒体信息需要巨大的空间开销,而许多编写WWW文档的人员并非专业的WWW开发人员,因而文档中包含了大量的图像连接,使用户在将入全部图像前不可能在起页作任何访问连接。WWW用户依赖文档或服务器的提供者去修改自制的信息,当没有对信息进行修改时,信息可能过时或出错。加上网上收集资料的经济条件限制、设备条件限制更多,带宽和传输速度的限制,用户要花大量的时间去等待,效率低下。此外,WWW搜索引擎在数据库、检索功能和应用上也存在一些局限性,与传统数据库人工搜集、人工标引相比,WWW数据库中数据主要由计算机自动搜集、标引,准确性和可靠性差,数据错误、遗漏、过时等问题较为常见。国内的中文搜索引擎尽管也有不少,但质量参差不齐,检索途径较为单一。此外,通用的搜索引擎采用的相关排序技术往往只是利用了一种排序方法,检索精度不高,国内网络信息资源匮乏,中文搜索引擎的研究开发和中文权威数据库的建设仍是国内的当务之急。 5 搜索引擎发展走向 因特网搜索引擎既是一门技术,又是一项服务,因此搜索引擎的发展应该包括搜索引擎产品技术的研发及其服务方式的改进与发展。但是,不管搜索引擎技术如何发展,服务方式如何改进,都不应偏离用户快速、准确、方便查找信息的主导方向。提供经过甄别、筛选、评价和专家推荐的网站信息无疑是高质量搜索引擎永恒不懈的追求,是搜索引擎智能化与专家系统交汇融合的结果。基于问题的搜索技术可能将成为未来搜索引擎发展的新趋势。从1994年Yahoo的运行到现在,搜索引擎取得了长足的发展与进步,无论是从数量上看还是从检索性能来看,都已经基本趋于成熟。虽然中文搜索引擎在产业化发展道路上还存在一些距离,但在搜索技术方面已不亚于国外搜索引擎。特别是在处理汉字上运用的切分标引技术、内码转换、词典标引技术、单汉字标引技术等独特技术与方法,使中文网络信息检索成为因特网上的一道亮丽的风景线。综合国内外搜索引擎研究与开发利用情况,搜索引擎的发展主要有以下趋势: 5.1大型综合性的搜索引擎与小型专业专题性搜索引擎协调发展 开发大型搜索引擎像Google、Yahoo和Altavista需要大量的人力、物力和财力,不是一般信息开发机构所能做到的,网上已有许多大型的优秀搜索引擎,中小型的信息开发机构和信息应用单位可充分利用网上现有的大型搜索引擎,经二次检索建立符合自己需要的小型专业性搜索引擎,来满足本行业本单位和本专业的需要。如可以搜集网上的医学图像,建立影像搜索引擎,也可以通过人工方式和利用搜索引擎结果,将因特网上的医学网站集中起来建立一个生物医学专题导航系统或生物医学搜索引擎。 5.2方便使用与查全率、查准率的协调发展 网络用户没有经过网络信息检索知识与技能的培训,对网络信息检索知识不了解,对为提高查全率和查准率而设置的各种检索句法和规则很难理解,因此,设计搜索引擎时要充分考虑各层次网络用户的使用水平,既要做到满足一定的查全与查准,又要尽量做到简化查询句法,查询界面清晰、有层次,给用户以更多的选择。 5.3概念检索、自然语言检索与精确检索、主题词语言检索协调发展 自然语言检索和概念检索是检索语言的两个不同的发展方向,可以分别满足不同用户对查全和查准的要求,自然语言检索则考虑的是方便用户的使用。国外已有不少医学搜索引擎使用了医学主题词表来支撑网络信息检索,能够实现由关键词或文本词向规范化主题词的自动转换(如PubMed),从而大大提高了医学搜索引擎的智能化程度。主题词语言与自然语言的协调发展和相互兼容也是大势所趋。 5.4制定分编网页内容的标准语言和格式并倡导实行 要提高网络信息资源的查全率和查准率,必须对网上最基本的资源单位如网页内容进行规范化和标准化处理,每个网页在发布之前,由网页的制作者或专门的人员,对该网页按照一定的标准进行规范,如网页的标题必须能够反映网页的内容,提取能反映网页内容的关键词放在特殊位置,编写网页摘要等。这样做不仅可以大大地提高网络资源的查全率与查准率,而且可以极大地降低搜索引擎加工网页的成本和时间。网上医学信息的规范化处理和标准化编目著录尤其重要,对医学专业网站和相关网页的标准化处理可以让用户放心大胆地使用这些医学信息。 5.5多途径检索 网上检索工具最初只是提供类目浏览和关键词检索,发展至今已成为能够检索多种类型信息的检索工具。医学图像信息的获取与利用,对于开展教育培训与继续医学教育有着非常重要的作用,国外一些大型搜索引擎提供了图像搜索的功能,生物医学搜索引擎特别要在提供图像搜索功能方面加大研究力度。 5.6多语种检索、本土化服务 随着上网用户的不断增加,世界各地上网人数不断增多,英语已无法满足所有用户的需要,语言障碍越来越明显。许多搜索引擎认识到这一点,正在相继加入多语种检索。与此同时,为解决信道拥挤、上网速度慢等问题,一些搜索引擎提供了本土化的检索服务,增加服务器,分流用户,提高上网查询速度。生物医学搜索引擎在本地化、本土化服务方面较大型通用搜索引擎还有很大一段距离,能够提供多语种检索的生物医学搜索引擎为数不多,以建立分站点或不同语言站点的方式来提供本土化服务的搜索引擎还很少。 5.7增加个性化服务与特色服务 个性化服务是指满足用户的特定需要。搜索引擎通过长期观察用户的搜索行为,能够从中识别用户的信息需求偏好,并且能够根据用户对搜索结果的评价,自觉调整搜索策略;在某些时候如用户所关心的信息发生变化时,自动发送电子邮件通知用户,保证用户能在第一时间获取最新的信息。搜索引擎的个性化服务可以帮助用户更快、更准确地找到所需信息,还可以避免无关信息的干扰,这其实也是搜索引擎智能化的一个方面。网上检索工具已不仅仅是单纯意义上的检索工具,正在向其它服务范畴扩展,提供站点评论、天气预报、新闻报道、股票点评、各种黄页(如电话号码、航班和列车时刻表、地图等)。那些主动向有关用户提供信息的服务项目具有较强的主动性和针对性,信息质量较高,用户不必在网络中漫无边际地查询,有些类似目前流行的信息推送技术。 5.8收费型与免费型搜索引擎并存 自搜索引擎出现以来,其提供的检索服务多为免费。但是随着因特网市场的发展壮大,搜索引擎作为一种网络服务,如同电子邮件一样,也会出现一些有偿的搜索服务。从长远发展来看,搜索引擎的部分有偿服务将有利于它的发展:技术开发商可以有更多的资金投入到技术研究与开发中,加快搜索引擎产品的更新换代;服务提供商可以通过与数据库厂商合作,有偿使用其数据库产品,从而加强自身数据库的建设。继Northernlight实行一头免费、一头收费的部分收费服务机制之后,Medical World Search这一医学搜索引擎也开始了收费服务。虽然目前大多数搜索引擎仍提供免费型服务,主要靠网路广告和提供搜索技术等来维持网站的运转,但收费型搜索引擎以其高质量的全文信息服务和低于联机检索和光盘检索的收费标准,使用户检索的信息在质量上有明显提高。因此,收费型与免费型搜索引擎还将同时存在,并彼此展开竞争,从而推动搜索引擎技术的发展和检索性能的改善。 5.9搜索引擎广泛吸纳信息技术人员参与,加强对搜索引擎检索信息质量的评价 对于搜索引擎的质量评价,更多的应依靠信息技术人员与图书馆人员,通过他们的参与制定具体、操作性强的量化指标体系来综合评价搜索引擎的质量,同时开展因特网医学信息的评价与评价标准的研究,使搜索引擎提供的检索结果更可信,质量更高。 5.10搜索引擎索及网页的质量控制将成为制约其发展的重要因素 随着网络信息资源的爆炸性增长,任何一个搜索引擎都不可能不加选择地从网上搜索新的网页和网站,制定网页质量评价指标及网页入选标准,并公诸于世。只有能满足用户信息需求的搜索引擎,才能更快速地发展。 5.11大型元搜索引擎的发展将格外引人注目,分布式搜索引擎研发市场前景看好 研建以多个搜索引擎甚至是多个元搜索引擎为主体的大型元搜索引擎,必将在提高网络信息覆盖率方面更胜一筹,同时也能包容更多的检索型搜索引擎,从而更大程度地满足网络用户查全率的要求。而分地区、分专题的分布式搜索引擎研发在降低网络带宽资源和其他设备资源方面有其优势和特色,因此对于分布式搜索引擎的研发将提上议事日程。随着国际大型资源合作编目组织如OCLC和中国CALIS中心的范围扩大,分布式搜索引擎的研发将变为现实。
6 开发中文搜索引擎的几点建议 必须大力提高中文搜索引擎自动搜索软件的智能化程度包括自然语言检索、概念查询和冗余检测能力,同时自动去除搜索站点不可链接的无效站点,确保网络站点的及时更新。经测试,网上中文搜索引擎都还不具备冗余检测功能,对于网址http://company.com/index.html和http://company.com/,很明显这两个网址是一样的,这类冗余通常很容易被忽略,又如个人主页网址经常含有“~”,而该符号可用代码%7E代表,如http://me.com/~jsmith和http://me.com/%7Ejsmith是同一网址,但这种冗余也检测不出,从我们的测试中也发现,所有的医学搜索引擎基本上还不具备概念检索或智能检索的功能,由于缺乏对关键词的规范控制,以致于单个搜索引擎很难查全相关的信息,因此需要一种智能化的冗余检测技术和进一步增强智能检索功能,实现自动剔除那些形式上不同但实质上相同的链接,真正实现自然语言的检索和概念检索。Internet上的变化迅速,但一些中文搜索引擎检索出的相关网站中还有不少无效的或过时的链接,或已更换了新的名称,或文档已转移至新的网站,搜索引擎还必须具备链接校验功能,能检测出这些无效的链接并将它们及时过滤或给出无效标记,方便网络用户使用,同时节省用户的上网时间。 国外一些搜索引擎和主题指南的多种文字版本已经出现,国内的网络指南针、万纬搜索等虽可实现中英语语种的检索,但对于不懂中文的网民来说,这一功能也和只能检索英文关键词的搜索引擎功能一样,没有更吸引人的服务方式。我们既要方便我国用户利用英文搜索引擎和主题指南,同时也要方便国外用户利用我国的中文搜索引擎和主题指南,因此有必要研制中外主要自然语言之间的对应转换工具。 搜索引擎和主题指南实质上是一种网页网址检索系统,其数据库中收录了几十万乃至数百万个网页网址,因此检索结果往往输出几千个乃至数十万个网址,虽可按相关性排序输出,但检准率较低。关键问题是标引用语和标引方法,大有改进的必要,同时有必要实现标引规范化和标准化。 规范网络资源的组织与控制,大力挖掘网络医学信息资源。由于网络资源的动态性、多样化及提取使用上的复杂性,网络界开发了一系列以检索资源为目标的元数据(metadata)格式(如Dublin core、URC),建立了一系列以详细描述资源为目标的元数据格式TEI header、GILS element standard、 SGML-DTD;网络资源组织控制则以搜索引擎方式为重点,此外还有Z39.50方式、GILS方式和X.500方式等,为此,我们必须重新分析设计信息组织的概念、内容、方式,尽快将信息组织和资源控制新技术新方法引入信息资源管理和信息服务工作实践,培训和培养大批适应未来信息组织与控制环境的专业人员与管理干部。 总之, 从目前的研究来看,改善搜索引擎的检索效果主要使用的是两大方法, 提高信息标引质量和改进检索机制,但收效并不明显。为此,一些研究人员陆续提出了改善信息检索效果的新方法,如智能检索软件的研制、自动数字图书馆员,主要是通过智能代理帮助用户制定选择检索工具、检索策略、进行检索操作、搜集并整理检索结果。Ask Jeeves 和Inquizit都能把用户的自然语言提问自动转换成检索提问,Inference Find能自动把检索结果根据其内容加以整理,归入相应的类别。国外一些学者的研究表明,一些专业搜索引擎的网页覆盖率和信息检准率较综合性搜索引擎为低,我们在对医学搜索引擎和通用搜索引擎检索医学信息方面的差异进行了比较研究,发现通用搜索引擎和医学搜索引擎的查准率都不高,但通用搜索引擎提供的有用信息却多于医学搜索引擎.。因此有必要进一步增加专业搜索引擎的网页覆盖范围,同时加强标引语言规范化和检索智能化的研究,通过精细检索和自然语言检索等方法提高查准率,并进一步开发出专业领域元搜索引擎,实现多个独立搜索引擎的并行检索,以提高网络信息的查全和查准率。搜索引擎网络化和加快其商业运作的步伐也是推动我国IT发展的重要措施,必须走优势互补、扬长避短、发挥特色和学科专业特长的合作开发、强强联合道路,才能蹄造中文搜索引擎的世界级门户网络通道,才能争取中文搜索引擎的持续发展。
参 考 文 献 [1] 储荷婷,张晓林,王 芳.Internet网络信息检索-原理 工具.北京:清华大学出版社,1999 [2] 曾民族.网络信息检索现状和性能评价.见:第十二届全国计算机情报管理学术讨论会会议论文集.1996:18-27 [3] 孟广均,沈 英, 郭志明等.信息资源管理导论.北京:科学出版社,1998 [4] 方 平,胡德华.一体化医学语言系统在医学科技信息检索中的应用.湖南医科大学学报(社会科学版),2000;(1):32-36 [5] 张琪玉.情报语言学领域亟待研究且潜藏较富的课题.图书馆杂志,1998;(增刊):149-155 [6] 秦 耕,白庆华,王 亭.WebLight:构筑在WWW信息塔尖上的信息检索系统.情报科学,2000;18(5):444-447 [7] 万跃华,王卫国.因特网最热门的检索工具:AltaVista搜索引擎.中国信息导报,1998;(11):43-46 [8] 朱建军.如何获取因特网中的生物医学信息资源.情报探索,1998;(2):30-31 [9] 张 颖,陈志农.因特网三大检索工具的比较研究.图书情报工作,1999;(10):39-42,58 [10] Gatlin L.How to make Internet searches easier:tips for effective use of web search engines. Am J Orthod Dentofacial ORthop, 1998; 114(3): 355-357 [11] 王 芳,张晓林.元搜索引擎:原理与应用.现代图书情报技 术, 1998,(6):18-21 [12] 翁惠玉,马范援,朱义军,等.网络搜索引擎的现状分析.情报学报,1999;18(增刊):100-102 [13] 沈红芳.互联网搜索引擎及其功能优化模型.情报科学,2000;18(1):7-9 [14] 朱义军,马范援,白英彩.分布式网络搜索引擎与Z39.50协议.世界网络与多 媒体;1999;7(1):46-47,58 [15] 张晓林.网络环境下信息资源组织与控制的新问题和新方向.图书馆杂志,1998;(增刊):200-212 [16] 吴校连,夏旭,黄开颜.生物医学搜索引擎与网络信息资源建设.上海:第二军医大学出版社,2002
以WWW网络搜索引擎的发展历程为基础,综述了WWW网络搜索引擎的定义、检索机制、检索规则、词表应用、分类研究、比较研究等方面取得的新进展,探讨搜索引擎发展走向与思路。同时就目前中外搜索引擎普遍存在的问题进行分析,希能对国内中文搜索引擎的开发和准确、快速、全面检索WWW网络乃至因特网信息资源有所启示。 关键词:搜索引擎 研究进展 综述 信息资源管理
由于因特网上信息资源内容广泛、时效性强、访问快速、网络交互搜寻、动态更新,而且还提供快速访问网上信息资源的各种搜索引擎(Search Engines),用于快速搜索WWW网络乃至因特上的有用信息,使得通过WWW网络获取网络信息资源成为国内外研究的一大热点。基于网络的搜索引擎的研制与开发应用成为当前网络信息资源开发应用研究领域的热点。英文搜索引擎“GOOGLE”和中文搜索引擎“百度搜索”的推出,拉开了搜索引擎核心技术争夺战的序幕。可以预言,在今后一段相当长的时间里,搜索引擎还将有长足的发展和进步,检索功能将更趋向于集成化和更具亲和力、更显人性化。 1 搜索引擎的定义、检索机制、检索规则和词表应用
1.1 定义
搜索引擎,Search engines,又称搜索机,Web搜索器,是伴随WWW网络出现的检索网上信息资源的新工具。实质上是一种网页网址检索系统,有的提供分类和关键词检索途径,有的仅提供关键词检索途径。它根据检索规则和从其他信息服务器上得到数据并对数据进行加工处理,自动建立索引,并通过检索接口为用户提供信息查询服务,能够自动对WWW资源建立索引或进行主题分类,并通过查询语法为用户返回匹配资源的系统。搜索引擎主要是由Crawler、Spider、Worm、Robot等计算机软件程序自动在因特网上漫游,不断搜集各类新网址及网页,形成数以千万甚至上亿条记录的数据库。它是通过采集标引众多网络站点来提供全局性网络资源控制与检索机制、将全球WWW网络中所有信息资源作一完整的集合、整理和分类、方便用户查找所需信息的网络检索软件。具有检索面广、信息量大、信息更新速度快,特定主题的检索专指性强等特点。 1.1.1 常规搜索引擎和元搜索引擎 自带索引数据库的搜索引擎通常被称为常规搜索引擎或独立搜索引擎,相应地,集多种常规搜索引擎于一体的搜索引擎则称为(多)元搜索引擎。元搜索引擎是国外搜索引擎开发者新设计的一种集成型搜索引擎,与独立搜索引擎的区别在于:它是通过一个统 一的用户界面帮助用户在多个独立搜索引擎中选择和利用合适的搜索引擎,甚至是同时利用多个搜索引擎来实现检索操作。元搜索引擎没有自己独立的数据库,却更多地提供统一界面,形成一个由多个搜索引擎构成的具有独立功能的虚拟逻辑体,通过元搜索引擎的功能实现对这个虚拟逻辑体中各搜索引擎数据库的查询等一切操作。由于元搜索引擎预先配置好多个搜索引擎,每条检索指令都自动通过预先配置 的搜索引擎执行,免去了用户逐一记忆和单独使用每个搜索引擎的麻烦。主要的元搜索引擎有ALL-IN-ONE、CUSI、Fun City Web Search、HyperNews、Linksearch、Savvysearch、Metacrawler、Best Search、W3Search Engines、WebSearch、Profusion、Mamma、Avenuesearch、Dogpile、Kwikseek、Findspot、Bytesearch、Webferret、Bluesquirrel Webseeker等。Metacrawler (http://www. metacrawler.com)能同时调用6个搜索引擎;Savvysearch (http://www. savvysearch.com)可有选择地调用21个独立的搜索引擎,检索Web、Usenet新闻组、软件、参考工具、技术报告等信息,每次最多并行检索5个搜索引擎的数据库。Profusion (http://www. profusion.com)最多同时调用9个独立的搜索引擎,调用方式有全部调用、系统自动选择最好的3个、系统自动选择最快的3个、用户从中选取任意个搜索引擎。最新出现的桌面型离线式搜索引擎如Webcompass、WebSeeker、WebFerret、Echosearch、Copernic98等也是元搜索引擎。 1.1.2 集中式搜索引擎和分布式搜索引擎 基于搜索机器人的搜索引擎如AltaVista和目录式搜索引擎Yahoo从体系结构上看都是集中式的,从因特网上取回Web页,经过处理后将所有这些信息集中存到某个站点,用户通过访问该站点实现查询,通常它们之间没有协作,各自独立地搜集和处理信息,造成了大量重复工作,也浪费了网络带宽和CPU资源,给各Web站点带来了严重的负担,这种集中式的体系结构难以适应网络规模的日益扩大。分布式搜索引擎则可弥补这方面的不足。其基本思想是根据地域、主题、IP地址或其它的划分标准将全网划分成若干自治域,在每个自治域内分设检索服务器(Index server),每个检索服务器由信息搜集软件(Gather)、索引数据库(Index database)和代理(Broker)三部分组成,信息搜索软件负责本自治域信息的搜集,并建立索引信息存入索引数据库,代理则负责向用户提供查询接口,并与其它代理进行交互,实现检索服务器之间的中间信息交换。关于分布式搜索引擎,目前主要以理论研究为主,还没有出现实际营运的研究成果。国内有文献提出建立分布协作式搜索引擎的设想,其主要思想是以CERNET为依托,在其不同域内分别建立搜索引擎,并通过引擎注册机制和引擎间数据交换机制相结合的方法实现网络搜索引擎之间的协作,达到降低资源消耗,提高搜索引擎效率的目的。 1.2 搜索引擎的检索机制 搜索引擎定期自动搜寻有关Web站点、采集关于这些站点上的各类信息,自动对这些资源进行标引、编制目录和文摘,自动将这些数据整合到数据库,并能提供以Web为基础的包括布尔检索、短语或词组检索、自然语言检索和各种限制检索在内的数据检索,按相关度输出检索结果 。搜索引擎的主体部分包括了数据采集模块、数据组织模块和数据检索模块。对应地,其资源组织和检索机制包括了数据采集标引机制、数据组织机制和用户检索机制,见图一。
1.3 检索规则研究
由于Web资源的特殊性,搜索引擎的检索语法和检索规则与传统的光盘检索和联机检索等有所不同。Medscape、Oncolink等医学搜索引擎通过AltaVista完成搜索任务。AltaVista的检索语法规则较为复杂,基本上囊括了医学搜索引擎的检索规则。Medscape和Oncolink为代表的搜索引擎检索规则主要包括:
布尔逻辑操作符。包括:AND(;、&)、OR(,、|)、NOT(—、!),此外逗号“,”类似于OR,空格和分号(;)类似于AND。
短语检索使用双引号,如“radiation enteritis”。如要查找数字信息,如“1 800 555 1212”,可用破折号“—”连接“1—800—555—1212”作为短语进行检索。
大小写有别(case-sensitivity),如输入brca1,可查找brca1,Brca1和BRCA1,如输入Brca1,则只能查找“Brca1”的网页,不能查找brca1、BRCA1的网页。
+/-号,如要查找乳腺癌治疗但非放射疗法的信息,输入breast+treatment-radiation进行精细检索。同样,如要查找异基因骨髓移植而非自体骨髓移植的信息,输入“bone marrow+allogeneic-autologous”即可。
截词检索,使用通配符“*”,也有使用“$”或“?”;英文句点“.”的作用正好与通配符相反,用于禁止单词扩展,如gene.不能检索genetics、genetic、general等词;
,2 搜索引擎的分类研究 WWW网络搜索引擎不仅数量增长快,而且种类也比较多。但目前尚无统一的分类标准。以下是一些主要的分类方法: 2.1 按索及资源内容的详略划分,有目录型、全文索引型、文摘型。 2.2 按索及资源的来源划分,有万维网和非万维网检索工具。 2.3 按覆盖范围划分,有通用查询引擎和专业查询引擎。 2.4 按检索方式划分,主要有关键词索引、主题指南和元搜索引擎 ,或按范畴层次查询的搜索引擎和词语查询引擎。有的将医学搜索引擎划分为目录型、检索型、评价型和汇集型,此外,还有作者将搜索引擎划分为分类主题目录、搜索引擎、主题索引、多种合一的集成检索工具。也有文献将其划分为检索型、目录型和混合型检索工具;或浏览式、按主题指南分类目录查询方式、利用检索软件进行关键词或自然语言的查询方式、集成式和多线索的查询。 2.5 按检索机制划分,有常规搜索引擎和元搜索引擎,或单独型和集合型检索工具;或人工分类式、自动搜寻式和混合式搜索引擎;或基于目录的搜索引擎、基于机器人的搜索引擎、基于客户的搜索引擎、元搜索引擎、分布式搜索引擎。离线式搜索软件需下载后安装运行方可进行检索,这类离线式搜索引擎多为元搜索引擎,主要有TURBOSTAT、WEBSEEKER,飓风搜索通、小猎狗、SEARCHX等中外离线式元搜索引擎。以上各类型搜索引擎,除分布式搜索引擎尚无实际营运的研究成果外,其他类型的搜索引擎均已有较多的实际应用。
3 搜索引擎的比较研究 搜索引擎的功能在于将分散的网址集中起来,分类提供给用户,以便快速查找到所需的信息。常规搜索引擎一般都带有数据库资源,因此对搜索引擎的比较主要集中在数据库资源和搜索引擎的性能两个方面。数据库资源方面的比较研究主要包括:数据库规模、索引方式、以及资源内容(如声音、图像、Usenet、FTP、Newsgroup、Gopher、Email等其它资源)。检索性能的比较,主要有布尔检索、复杂布尔检索、相邻和相邻and/or检索(NEAR、ADJ、FAR、BEFORE、FOLLOWED BY、
| 搜索引擎及网址 | 开发公司 | 运行时间 | 网页数 | 检索功能 | 结果显示 |
| Google(http://www.google.com) | 1998 | 33亿网页 | 简单、高级检索、精确检索、网站定位 | 标准、相关性排序、页显示结果数可选择 | |
| Altavista(http://www. alvista.digital.com) | 美国数字 设备公司 | 1995.12 | 1亿多网页 | 简单、高级检索、精确检索 | 标准、压缩、详细格式、页显示条数可选择 |
| Lycos(http://www.lycos. com) | 美国卡内基 梅隆大学 | 1994.5 | 6600万余网页 | 自然语言、布尔、截词检索 | 结果显示可选择 |
| Excite(http://www.excite.com) | Architext 软件公司 | 1995 | 5500万网页 | 自然语言,布尔检索、概念查询,精确检索 | 检索结果带文摘,数量和质量均较理想。 |
| Yahoo(http://www.yahoo. com) | 美国斯坦福大学 | 1994 | 5000万 网页 | 主题,关键词检索、布尔、精确检索 | 简短描述,检索结果较好,但数量不多。 |
| Infoseek(http://www.info seek.com) | 美国Infoseek公司 | 1995 | 5000万 网页 | 主题分类、关键词 查询 | 相关性排序,结果有描述、较详细。收费 |
| Webcrawler(http://www.webcrawler.com) | 华盛顿大学 | 1994 | 200万网页 | 自然语言、布尔检索NEAR、ADJ检索 | 相关性排序,简单、详细格式结果数量大 |
| Magellan(http://www.magellan.com) | 美国Magellan公司 | 自然语言、布尔检索 | 详细的信息描述结果显示网站打分 | ||
| HotBot(http://www.hot bot.com) | Lycos network | 5400万网页 | 布尔运算、关键词 | 无相关排序 | |
| Inktomi(http://inktomi.berkeley.edu) | Inktomi公司 | 1996.2 | 280万网页 | 关键词、词根检索;+/-表必用或禁用词 | 智能相关排序,有描述:无摘要 |
| Medicalmatrix(http://www Medmatrix.org) | Healthitel 公司 | 5000多个医学站点 | 分类、关键词检索 | 简单、详细格式 | |
| 搜狐(http://www.sohu com) | 爱特信公司 | 1998.2 | 200万网页 | 分类查询、关键词 | 标准、简要格式 |
| 百度(http://www.baidu.com) | 百度网络公司 | 1999 | 4500万网页 | 分类浏览、简单、高级检索 | 详细格式、有描述,相关性排序 |
| 天网(http://pccms.pku edu.cn:8000/gbindex.htm) | 北京大学 计算机系 | 100万网页 | 简单、高级查询、查词串查询率高 | 命中率高,重复网页多相关性排序,标准/简要 | |
| Goyoyo(http://www.Goyoyo.com.cn) | 香港优联克、 北京联克公司 | 1997 | 24万中文 网页 | 关键词、分类主题 | 网页过滤、详细格式 |
4 存在的问题 WWW搜索引擎的分类方法不统一,缺乏权威的分类标准,国内有关WWW搜索引擎的分类研究更显薄弱。 无论从评价标准、评价方法和评价范围来看,目前的研究还不够深入,尽管有大量的搜索引擎比较研究论文,由于缺乏统一的标准和权威的评价指标体系,还要从理论上进行深入探讨,并开展更具规模和系统性的分析和评价工作,形成权威的评价站点和搜索引擎性能评价指标体系。目前国内还没有出现WWW网上的权威评价站点,国内的搜索引擎评价标准多是综合或借鉴了国外的研究成果,有所创新的评价研究和评价指标并不多见,网络中文信息资源和搜索引擎性能评价也还刚刚起步。当然,网上中文信息匮乏也是带普遍性的问题。在国际数据库市场中,数据库产品的地区分布为北美占64%、西欧占28%、亚洲占4%、澳洲占2%、非洲和南美洲1%;发展中国家对数据库的占有量不到5%,在亚洲只有日本、韩国有100种以上的数据库产品进入国际数据库市场,各为143、132种,中国只有4种。在国际各类数据库中,11.26%的数据库在100万条记录以上,其中超过1亿条记录的占0.36%,2.78%的数据库在1000万-1亿条之间,8.03%的数据在100万-1000万条间。除了大型数据库外,其余数据库平均记录在11.3万条左右;国内29家单位142个数据库的调查表明,10万条以下的数据库占72.32%,大型数据库仅占5.6%,尚无超过1000万条记录的数据库。中文信息不全,质量不高,也是制约中文搜索引擎进一步发展并推向国际市场的重大障碍。 WWW搜索引擎的选择也是仁者见仁,智者见智,多是根据经验的初步选择,还没有形成一套固定的选择原则和方法。WWW信息查询还不可能取代技术成熟的联机检索和光盘检索。据估计,因特网上目前有3000万URL和35亿页文件,而且文件数量每年增加一倍,迄今搜索引擎尚存在以下主要的问题:即使最强有力的搜索引擎也只能覆盖其中的1/3;查准率不高,检索精度不如传统检索系统;更新速度慢而且无法控制网络信息的动态变化;此外对信息内容的表达和格式的多样化难于控制和管理。 WWW中文搜索引擎带有的数据库容量小,尚未形成大型的检索系统,大型、综合、集成的元搜索引擎还没有开发出来,专业性和专题性中文搜索引擎亟需研究开发。基于WWW的因特网检索越来越普遍,信息过载成为日益紧迫的研究问题;电子期刊全文数据库提供的信息时滞参差不齐、蕴含的信息量少于印刷本期刊。 信息组织的局部有序性与整体无序性。各搜索引擎和站点目录都收集大量的站点,并按专业和文献信息类型分类,实现了信息组织的局部有序化,但仍有大量信息被湮灭在信息的海洋里,这种无序性导致了网络信息检索的系统性和完整性不如商用联机检索系统,此外,有害信息(黄色、吸毒、暴力宣扬)多,不安全因素有增无减,缺少一个统一的监督机构,信息泛滥造成了信息污染和资源、时间的浪费。多媒体信息需要巨大的空间开销,而许多编写WWW文档的人员并非专业的WWW开发人员,因而文档中包含了大量的图像连接,使用户在将入全部图像前不可能在起页作任何访问连接。WWW用户依赖文档或服务器的提供者去修改自制的信息,当没有对信息进行修改时,信息可能过时或出错。加上网上收集资料的经济条件限制、设备条件限制更多,带宽和传输速度的限制,用户要花大量的时间去等待,效率低下。此外,WWW搜索引擎在数据库、检索功能和应用上也存在一些局限性,与传统数据库人工搜集、人工标引相比,WWW数据库中数据主要由计算机自动搜集、标引,准确性和可靠性差,数据错误、遗漏、过时等问题较为常见。国内的中文搜索引擎尽管也有不少,但质量参差不齐,检索途径较为单一。此外,通用的搜索引擎采用的相关排序技术往往只是利用了一种排序方法,检索精度不高,国内网络信息资源匮乏,中文搜索引擎的研究开发和中文权威数据库的建设仍是国内的当务之急。 5 搜索引擎发展走向 因特网搜索引擎既是一门技术,又是一项服务,因此搜索引擎的发展应该包括搜索引擎产品技术的研发及其服务方式的改进与发展。但是,不管搜索引擎技术如何发展,服务方式如何改进,都不应偏离用户快速、准确、方便查找信息的主导方向。提供经过甄别、筛选、评价和专家推荐的网站信息无疑是高质量搜索引擎永恒不懈的追求,是搜索引擎智能化与专家系统交汇融合的结果。基于问题的搜索技术可能将成为未来搜索引擎发展的新趋势。从1994年Yahoo的运行到现在,搜索引擎取得了长足的发展与进步,无论是从数量上看还是从检索性能来看,都已经基本趋于成熟。虽然中文搜索引擎在产业化发展道路上还存在一些距离,但在搜索技术方面已不亚于国外搜索引擎。特别是在处理汉字上运用的切分标引技术、内码转换、词典标引技术、单汉字标引技术等独特技术与方法,使中文网络信息检索成为因特网上的一道亮丽的风景线。综合国内外搜索引擎研究与开发利用情况,搜索引擎的发展主要有以下趋势: 5.1大型综合性的搜索引擎与小型专业专题性搜索引擎协调发展 开发大型搜索引擎像Google、Yahoo和Altavista需要大量的人力、物力和财力,不是一般信息开发机构所能做到的,网上已有许多大型的优秀搜索引擎,中小型的信息开发机构和信息应用单位可充分利用网上现有的大型搜索引擎,经二次检索建立符合自己需要的小型专业性搜索引擎,来满足本行业本单位和本专业的需要。如可以搜集网上的医学图像,建立影像搜索引擎,也可以通过人工方式和利用搜索引擎结果,将因特网上的医学网站集中起来建立一个生物医学专题导航系统或生物医学搜索引擎。 5.2方便使用与查全率、查准率的协调发展 网络用户没有经过网络信息检索知识与技能的培训,对网络信息检索知识不了解,对为提高查全率和查准率而设置的各种检索句法和规则很难理解,因此,设计搜索引擎时要充分考虑各层次网络用户的使用水平,既要做到满足一定的查全与查准,又要尽量做到简化查询句法,查询界面清晰、有层次,给用户以更多的选择。 5.3概念检索、自然语言检索与精确检索、主题词语言检索协调发展 自然语言检索和概念检索是检索语言的两个不同的发展方向,可以分别满足不同用户对查全和查准的要求,自然语言检索则考虑的是方便用户的使用。国外已有不少医学搜索引擎使用了医学主题词表来支撑网络信息检索,能够实现由关键词或文本词向规范化主题词的自动转换(如PubMed),从而大大提高了医学搜索引擎的智能化程度。主题词语言与自然语言的协调发展和相互兼容也是大势所趋。 5.4制定分编网页内容的标准语言和格式并倡导实行 要提高网络信息资源的查全率和查准率,必须对网上最基本的资源单位如网页内容进行规范化和标准化处理,每个网页在发布之前,由网页的制作者或专门的人员,对该网页按照一定的标准进行规范,如网页的标题必须能够反映网页的内容,提取能反映网页内容的关键词放在特殊位置,编写网页摘要等。这样做不仅可以大大地提高网络资源的查全率与查准率,而且可以极大地降低搜索引擎加工网页的成本和时间。网上医学信息的规范化处理和标准化编目著录尤其重要,对医学专业网站和相关网页的标准化处理可以让用户放心大胆地使用这些医学信息。 5.5多途径检索 网上检索工具最初只是提供类目浏览和关键词检索,发展至今已成为能够检索多种类型信息的检索工具。医学图像信息的获取与利用,对于开展教育培训与继续医学教育有着非常重要的作用,国外一些大型搜索引擎提供了图像搜索的功能,生物医学搜索引擎特别要在提供图像搜索功能方面加大研究力度。 5.6多语种检索、本土化服务 随着上网用户的不断增加,世界各地上网人数不断增多,英语已无法满足所有用户的需要,语言障碍越来越明显。许多搜索引擎认识到这一点,正在相继加入多语种检索。与此同时,为解决信道拥挤、上网速度慢等问题,一些搜索引擎提供了本土化的检索服务,增加服务器,分流用户,提高上网查询速度。生物医学搜索引擎在本地化、本土化服务方面较大型通用搜索引擎还有很大一段距离,能够提供多语种检索的生物医学搜索引擎为数不多,以建立分站点或不同语言站点的方式来提供本土化服务的搜索引擎还很少。 5.7增加个性化服务与特色服务 个性化服务是指满足用户的特定需要。搜索引擎通过长期观察用户的搜索行为,能够从中识别用户的信息需求偏好,并且能够根据用户对搜索结果的评价,自觉调整搜索策略;在某些时候如用户所关心的信息发生变化时,自动发送电子邮件通知用户,保证用户能在第一时间获取最新的信息。搜索引擎的个性化服务可以帮助用户更快、更准确地找到所需信息,还可以避免无关信息的干扰,这其实也是搜索引擎智能化的一个方面。网上检索工具已不仅仅是单纯意义上的检索工具,正在向其它服务范畴扩展,提供站点评论、天气预报、新闻报道、股票点评、各种黄页(如电话号码、航班和列车时刻表、地图等)。那些主动向有关用户提供信息的服务项目具有较强的主动性和针对性,信息质量较高,用户不必在网络中漫无边际地查询,有些类似目前流行的信息推送技术。 5.8收费型与免费型搜索引擎并存 自搜索引擎出现以来,其提供的检索服务多为免费。但是随着因特网市场的发展壮大,搜索引擎作为一种网络服务,如同电子邮件一样,也会出现一些有偿的搜索服务。从长远发展来看,搜索引擎的部分有偿服务将有利于它的发展:技术开发商可以有更多的资金投入到技术研究与开发中,加快搜索引擎产品的更新换代;服务提供商可以通过与数据库厂商合作,有偿使用其数据库产品,从而加强自身数据库的建设。继Northernlight实行一头免费、一头收费的部分收费服务机制之后,Medical World Search这一医学搜索引擎也开始了收费服务。虽然目前大多数搜索引擎仍提供免费型服务,主要靠网路广告和提供搜索技术等来维持网站的运转,但收费型搜索引擎以其高质量的全文信息服务和低于联机检索和光盘检索的收费标准,使用户检索的信息在质量上有明显提高。因此,收费型与免费型搜索引擎还将同时存在,并彼此展开竞争,从而推动搜索引擎技术的发展和检索性能的改善。 5.9搜索引擎广泛吸纳信息技术人员参与,加强对搜索引擎检索信息质量的评价 对于搜索引擎的质量评价,更多的应依靠信息技术人员与图书馆人员,通过他们的参与制定具体、操作性强的量化指标体系来综合评价搜索引擎的质量,同时开展因特网医学信息的评价与评价标准的研究,使搜索引擎提供的检索结果更可信,质量更高。 5.10搜索引擎索及网页的质量控制将成为制约其发展的重要因素 随着网络信息资源的爆炸性增长,任何一个搜索引擎都不可能不加选择地从网上搜索新的网页和网站,制定网页质量评价指标及网页入选标准,并公诸于世。只有能满足用户信息需求的搜索引擎,才能更快速地发展。 5.11大型元搜索引擎的发展将格外引人注目,分布式搜索引擎研发市场前景看好 研建以多个搜索引擎甚至是多个元搜索引擎为主体的大型元搜索引擎,必将在提高网络信息覆盖率方面更胜一筹,同时也能包容更多的检索型搜索引擎,从而更大程度地满足网络用户查全率的要求。而分地区、分专题的分布式搜索引擎研发在降低网络带宽资源和其他设备资源方面有其优势和特色,因此对于分布式搜索引擎的研发将提上议事日程。随着国际大型资源合作编目组织如OCLC和中国CALIS中心的范围扩大,分布式搜索引擎的研发将变为现实。
6 开发中文搜索引擎的几点建议 必须大力提高中文搜索引擎自动搜索软件的智能化程度包括自然语言检索、概念查询和冗余检测能力,同时自动去除搜索站点不可链接的无效站点,确保网络站点的及时更新。经测试,网上中文搜索引擎都还不具备冗余检测功能,对于网址http://company.com/index.html和http://company.com/,很明显这两个网址是一样的,这类冗余通常很容易被忽略,又如个人主页网址经常含有“~”,而该符号可用代码%7E代表,如http://me.com/~jsmith和http://me.com/%7Ejsmith是同一网址,但这种冗余也检测不出,从我们的测试中也发现,所有的医学搜索引擎基本上还不具备概念检索或智能检索的功能,由于缺乏对关键词的规范控制,以致于单个搜索引擎很难查全相关的信息,因此需要一种智能化的冗余检测技术和进一步增强智能检索功能,实现自动剔除那些形式上不同但实质上相同的链接,真正实现自然语言的检索和概念检索。Internet上的变化迅速,但一些中文搜索引擎检索出的相关网站中还有不少无效的或过时的链接,或已更换了新的名称,或文档已转移至新的网站,搜索引擎还必须具备链接校验功能,能检测出这些无效的链接并将它们及时过滤或给出无效标记,方便网络用户使用,同时节省用户的上网时间。 国外一些搜索引擎和主题指南的多种文字版本已经出现,国内的网络指南针、万纬搜索等虽可实现中英语语种的检索,但对于不懂中文的网民来说,这一功能也和只能检索英文关键词的搜索引擎功能一样,没有更吸引人的服务方式。我们既要方便我国用户利用英文搜索引擎和主题指南,同时也要方便国外用户利用我国的中文搜索引擎和主题指南,因此有必要研制中外主要自然语言之间的对应转换工具。 搜索引擎和主题指南实质上是一种网页网址检索系统,其数据库中收录了几十万乃至数百万个网页网址,因此检索结果往往输出几千个乃至数十万个网址,虽可按相关性排序输出,但检准率较低。关键问题是标引用语和标引方法,大有改进的必要,同时有必要实现标引规范化和标准化。 规范网络资源的组织与控制,大力挖掘网络医学信息资源。由于网络资源的动态性、多样化及提取使用上的复杂性,网络界开发了一系列以检索资源为目标的元数据(metadata)格式(如Dublin core、URC),建立了一系列以详细描述资源为目标的元数据格式TEI header、GILS element standard、 SGML-DTD;网络资源组织控制则以搜索引擎方式为重点,此外还有Z39.50方式、GILS方式和X.500方式等,为此,我们必须重新分析设计信息组织的概念、内容、方式,尽快将信息组织和资源控制新技术新方法引入信息资源管理和信息服务工作实践,培训和培养大批适应未来信息组织与控制环境的专业人员与管理干部。 总之, 从目前的研究来看,改善搜索引擎的检索效果主要使用的是两大方法, 提高信息标引质量和改进检索机制,但收效并不明显。为此,一些研究人员陆续提出了改善信息检索效果的新方法,如智能检索软件的研制、自动数字图书馆员,主要是通过智能代理帮助用户制定选择检索工具、检索策略、进行检索操作、搜集并整理检索结果。Ask Jeeves 和Inquizit都能把用户的自然语言提问自动转换成检索提问,Inference Find能自动把检索结果根据其内容加以整理,归入相应的类别。国外一些学者的研究表明,一些专业搜索引擎的网页覆盖率和信息检准率较综合性搜索引擎为低,我们在对医学搜索引擎和通用搜索引擎检索医学信息方面的差异进行了比较研究,发现通用搜索引擎和医学搜索引擎的查准率都不高,但通用搜索引擎提供的有用信息却多于医学搜索引擎.。因此有必要进一步增加专业搜索引擎的网页覆盖范围,同时加强标引语言规范化和检索智能化的研究,通过精细检索和自然语言检索等方法提高查准率,并进一步开发出专业领域元搜索引擎,实现多个独立搜索引擎的并行检索,以提高网络信息的查全和查准率。搜索引擎网络化和加快其商业运作的步伐也是推动我国IT发展的重要措施,必须走优势互补、扬长避短、发挥特色和学科专业特长的合作开发、强强联合道路,才能蹄造中文搜索引擎的世界级门户网络通道,才能争取中文搜索引擎的持续发展。
参 考 文 献 [1] 储荷婷,张晓林,王 芳.Internet网络信息检索-原理 工具.北京:清华大学出版社,1999 [2] 曾民族.网络信息检索现状和性能评价.见:第十二届全国计算机情报管理学术讨论会会议论文集.1996:18-27 [3] 孟广均,沈 英, 郭志明等.信息资源管理导论.北京:科学出版社,1998 [4] 方 平,胡德华.一体化医学语言系统在医学科技信息检索中的应用.湖南医科大学学报(社会科学版),2000;(1):32-36 [5] 张琪玉.情报语言学领域亟待研究且潜藏较富的课题.图书馆杂志,1998;(增刊):149-155 [6] 秦 耕,白庆华,王 亭.WebLight:构筑在WWW信息塔尖上的信息检索系统.情报科学,2000;18(5):444-447 [7] 万跃华,王卫国.因特网最热门的检索工具:AltaVista搜索引擎.中国信息导报,1998;(11):43-46 [8] 朱建军.如何获取因特网中的生物医学信息资源.情报探索,1998;(2):30-31 [9] 张 颖,陈志农.因特网三大检索工具的比较研究.图书情报工作,1999;(10):39-42,58 [10] Gatlin L.How to make Internet searches easier:tips for effective use of web search engines. Am J Orthod Dentofacial ORthop, 1998; 114(3): 355-357 [11] 王 芳,张晓林.元搜索引擎:原理与应用.现代图书情报技 术, 1998,(6):18-21 [12] 翁惠玉,马范援,朱义军,等.网络搜索引擎的现状分析.情报学报,1999;18(增刊):100-102 [13] 沈红芳.互联网搜索引擎及其功能优化模型.情报科学,2000;18(1):7-9 [14] 朱义军,马范援,白英彩.分布式网络搜索引擎与Z39.50协议.世界网络与多 媒体;1999;7(1):46-47,58 [15] 张晓林.网络环境下信息资源组织与控制的新问题和新方向.图书馆杂志,1998;(增刊):200-212 [16] 吴校连,夏旭,黄开颜.生物医学搜索引擎与网络信息资源建设.上海:第二军医大学出版社,2002
|
|||||||
| |||||||



